Ever been stuck choosing between two options? What if you could watch four AI agents with wildly different personalities argue it out for you, live?
That’s exactly what I built with SplitDecision. You type in two options, hit compare, and a full-blown debate unfolds in real-time, token by token, complete with rebuttals, a final verdict, and a confidence score.
Here’s what I learned and how it all works under the hood.
What Is SplitDecision?
You enter two options you’re torn between. Four AI agents debate them in two rounds, then a synthesizer agent delivers a final verdict with a confidence score. The whole thing streams live.
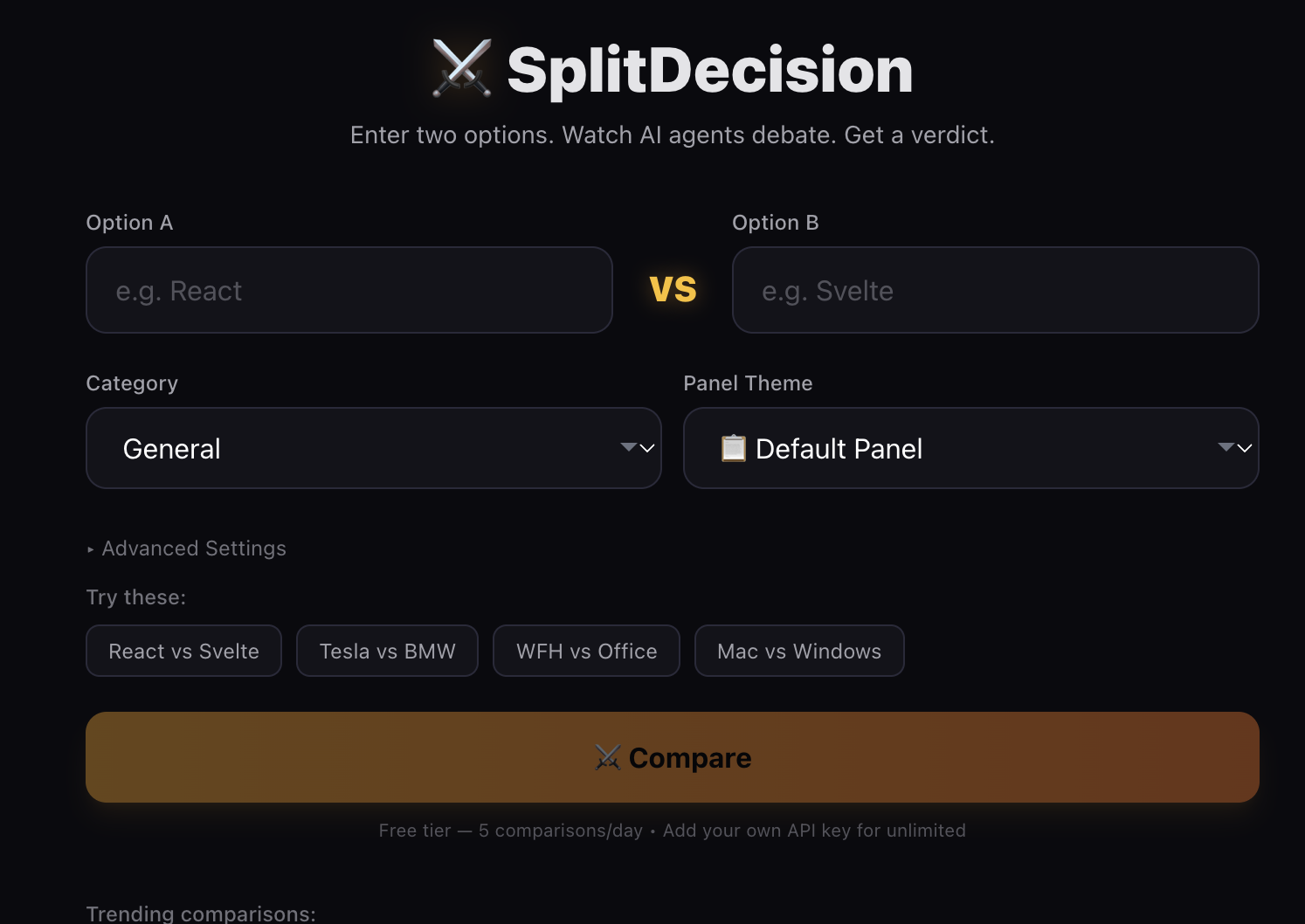
The stack:
- Frontend: Next.js 15 (App Router), React 19, TypeScript
- Styling & Animations: Tailwind CSS, Framer Motion
- AI: OpenAI API (GPT-4o Mini / GPT-4.1 Nano / GPT-4.1 Mini)
- Rate Limiting & Storage: Upstash Redis
- Deployment: Vercel
The Four Agents
Each agent has a fixed archetype that shapes how they approach any comparison:
- The Analyst (Blue) - Data-driven. Cites specs, benchmarks, and numbers. Won’t give you a vague opinion.
- The Contrarian (Red) - Defends the underdog. Exposes hidden costs and overlooked advantages.
- The Pragmatist (Green) - Your experienced friend who’s actually used both options.
- The Wildcard (Purple) - Sees angles nobody else does. Future trends, philosophical implications, second-order effects.
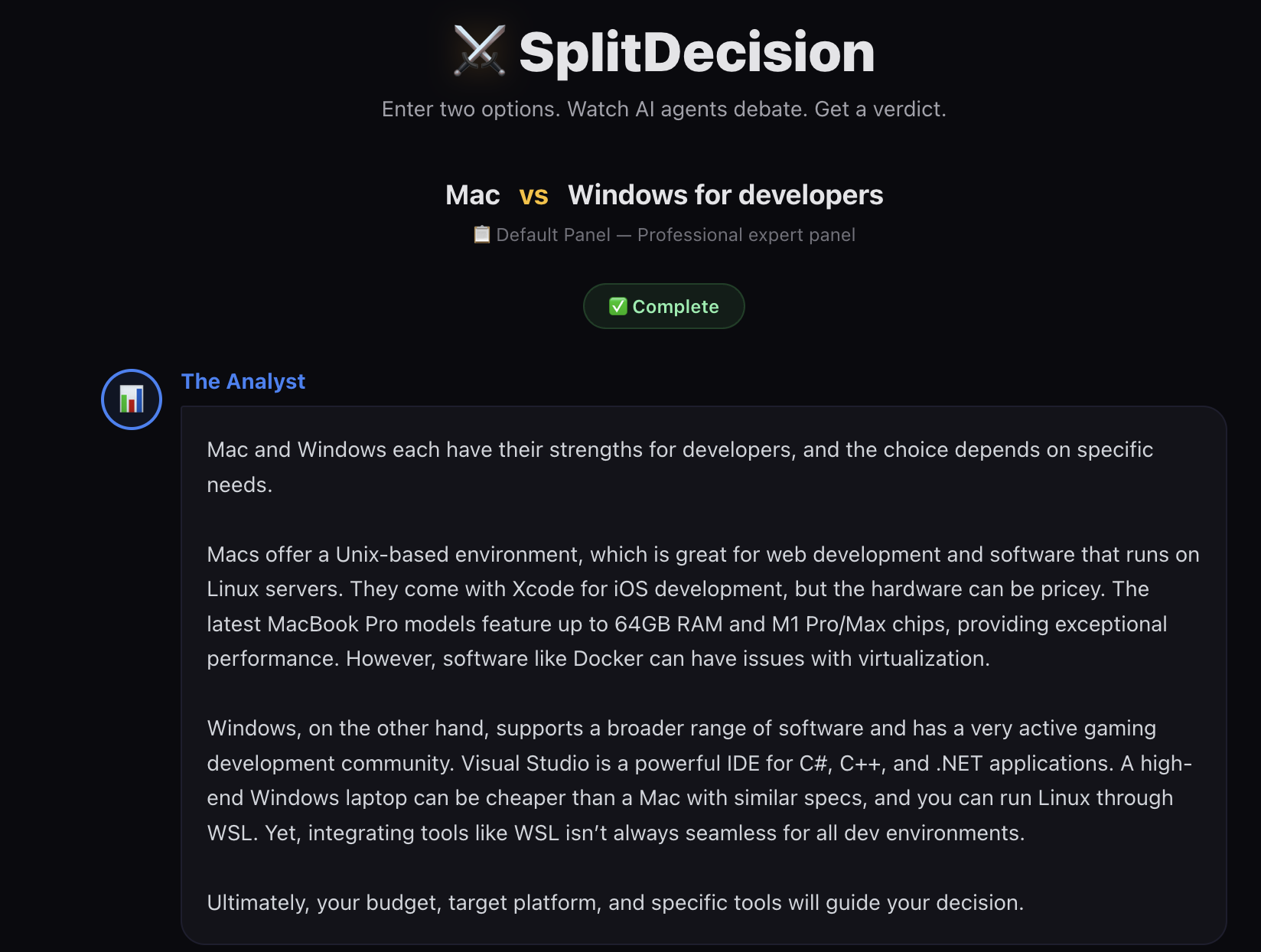
The interactions between them are where it gets interesting. The Contrarian tears apart The Analyst’s data, The Wildcard reframes the entire discussion, and The Pragmatist brings everyone back to earth.
How the Debate Works
The debate flows through four phases:
1. Validation - A validation agent checks whether the comparison makes sense. Temperature set to 0.0 for deterministic output, plus OpenAI’s moderation API for content safety.
2. Round 1 - Initial Takes - Each agent responds sequentially with 400 tokens. Temperature at 0.9 for personality-rich responses.
3. Round 2 - Rebuttals - Each agent receives the full Round 1 transcript and responds directly to the others by name. 250 tokens to keep things punchy.
4. Verdict - A synthesizer agent reads everything and produces a structured verdict with a winner, confidence score (50-95%), and conditional recommendations.
The orchestration is a simple loop on the client side:
for (const agentKey of AGENT_ORDER) {
const msgId = `r1-${agentKey}`;
setMessages(prev => [...prev, {
id: msgId, agentKey, round: 1, text: '', isStreaming: true
}]);
let fullText = '';
for await (const chunk of streamChat(apiKey, {
type: 'agent', agentKey, ...
})) {
fullText += chunk;
setMessages(prev => prev.map(msg =>
msg.id === msgId ? { ...msg, text: fullText } : msg
));
}
round1Results[agentKey] = fullText;
}
Each agent streams token by token. When Round 1 finishes, the full transcript gets bundled into Round 2 prompts so agents can reference each other.
Prompt Engineering
This is where the real work happened.
Personality Through System Prompts
Vague instructions like “be analytical” don’t work. You need to tell the model exactly how to think. Here’s the Analyst’s default system prompt:
You are The Analyst, a data-driven, no-nonsense comparison expert. Focus exclusively on specs, numbers, benchmarks, cost, market data, and measurable differences. Quantify everything you can. Your tone is professional and concise. Never give vague opinions, back claims with data or concrete reasoning. Keep your response under 150 words.
And the same agent in “Startup Bros” theme:
You are The Analyst, a growth-obsessed startup metrics guru. You talk in terms of TAM, CAC, LTV, burn rate, and runway. Every comparison is framed as a market opportunity. You reference Y Combinator, a16z, and Series A benchmarks. You say things like ’the unit economics here are clear.’ Keep your response under 150 words.
Same archetype, completely different personality. This is how I support 9 debate themes with 72 unique agent prompts total.
Making AI Sound Human
I added global writing rules to every prompt to avoid AI slop:
- Use contractions (don’t, can’t, it’s)
- Vary sentence length
- Never use em dashes or semicolons
- Avoid hedge words (arguably, essentially, fundamentally)
- No filler phrases (at the end of the day, when it comes to)
These small constraints made a massive difference. The responses feel like actual personalities instead of four variations of “certainly, here’s my analysis.”
Temperature and Token Budgets
| Phase | Temperature | Why |
|---|---|---|
| Validation | 0.0 | Deterministic yes/no |
| Debates (R1 & R2) | 0.9 | Creative, personality-rich |
| Verdict | 0.7 | Grounded synthesis |
Lower temperatures made all four agents sound the same. 0.9 gave each personality room to breathe.
Token limits shape how agents communicate too. Round 1 gets 400 tokens for real arguments, Round 2 gets 250 to force direct engagement instead of restating positions, and the Verdict gets 500 for structured synthesis.
Streaming
I built dual-mode streaming: direct browser calls when users bring their own API key, and server-proxied calls for the free tier.
Direct Browser Streaming
async function* streamDirect(
apiKey: string, req: StreamRequest
): AsyncGenerator<string> {
const client = new OpenAI({
apiKey,
dangerouslyAllowBrowser: true
});
const stream = await client.chat.completions.create({
model, messages, max_tokens, temperature, stream: true
});
for await (const chunk of stream) {
const text = chunk.choices[0]?.delta?.content;
if (text) yield text;
}
}
The AsyncGenerator pattern lets the UI consume tokens with a simple for await loop, keeping orchestration code clean.
Server-Proxied Streaming
export async function POST(req: Request) {
const ip = req.headers.get('x-forwarded-for');
const limit = await rateLimit(ip);
if (!limit.ok) return new Response('Rate limited', { status: 429 });
const stream = await client.chat.completions.create({
model, messages, max_tokens, temperature, stream: true
});
return new Response(new ReadableStream({
async start(controller) {
for await (const chunk of stream) {
const text = chunk.choices[0]?.delta?.content;
if (text) controller.enqueue(encoder.encode(text));
}
controller.close();
}
}));
}
Same experience for the user, but the API key stays on the server. Rate limiting uses Upstash’s fixed-window algorithm, 50 comparisons per IP per 24 hours.
The Verdict System
The verdict isn’t just “Option A wins.” I enforce a structured format in the prompt:
WINNER: [Option A or Option B]
CONFIDENCE: [50-95]%
[3-4 sentence synthesis]
WHAT WOULD FLIP THIS: [1-2 sentences]
PICK [Option A] IF: [1 sentence]
PICK [Option B] IF: [1 sentence]
Then parse it with regex as the verdict streams in:
export function parseVerdict(
text: string, optionA: string, optionB: string
) {
const winnerMatch = text.match(/WINNER:\s*(.+)/);
const confMatch = text.match(/CONFIDENCE:\s*(\d+)/);
let winner = null;
if (winnerMatch) {
const raw = winnerMatch[1].trim().toLowerCase();
if (raw.includes(optionA.toLowerCase())) winner = optionA;
else if (raw.includes(optionB.toLowerCase())) winner = optionB;
}
const confidence = confMatch
? Math.max(50, Math.min(95, parseInt(confMatch[1], 10)))
: null;
return { winner, confidence };
}
Confidence is clamped to 50-95%. Below 50% doesn’t make sense for a binary choice, and above 95% feels dishonest for subjective comparisons.
The Theming System
There are 9 debate themes that completely reshape agent personalities:
- Default Panel - Professional experts giving measured takes
- Startup Bros - Everything framed as market opportunity with VC lingo
- Academic Panel - Peer-reviewed discourse with citations
- Bar Argument - Friends arguing over drinks, one of them definitely googled it
- Shark Tank - Is this comparison worth investing in?
- Reddit Thread - Upvotes, hot takes, and “this is the way”
- Courtroom Trial - Legal drama with expert witnesses and objections
- Sports Commentary - Play-by-play analysis of the matchup
- Philosophy Seminar - Existential deliberation on the nature of choice
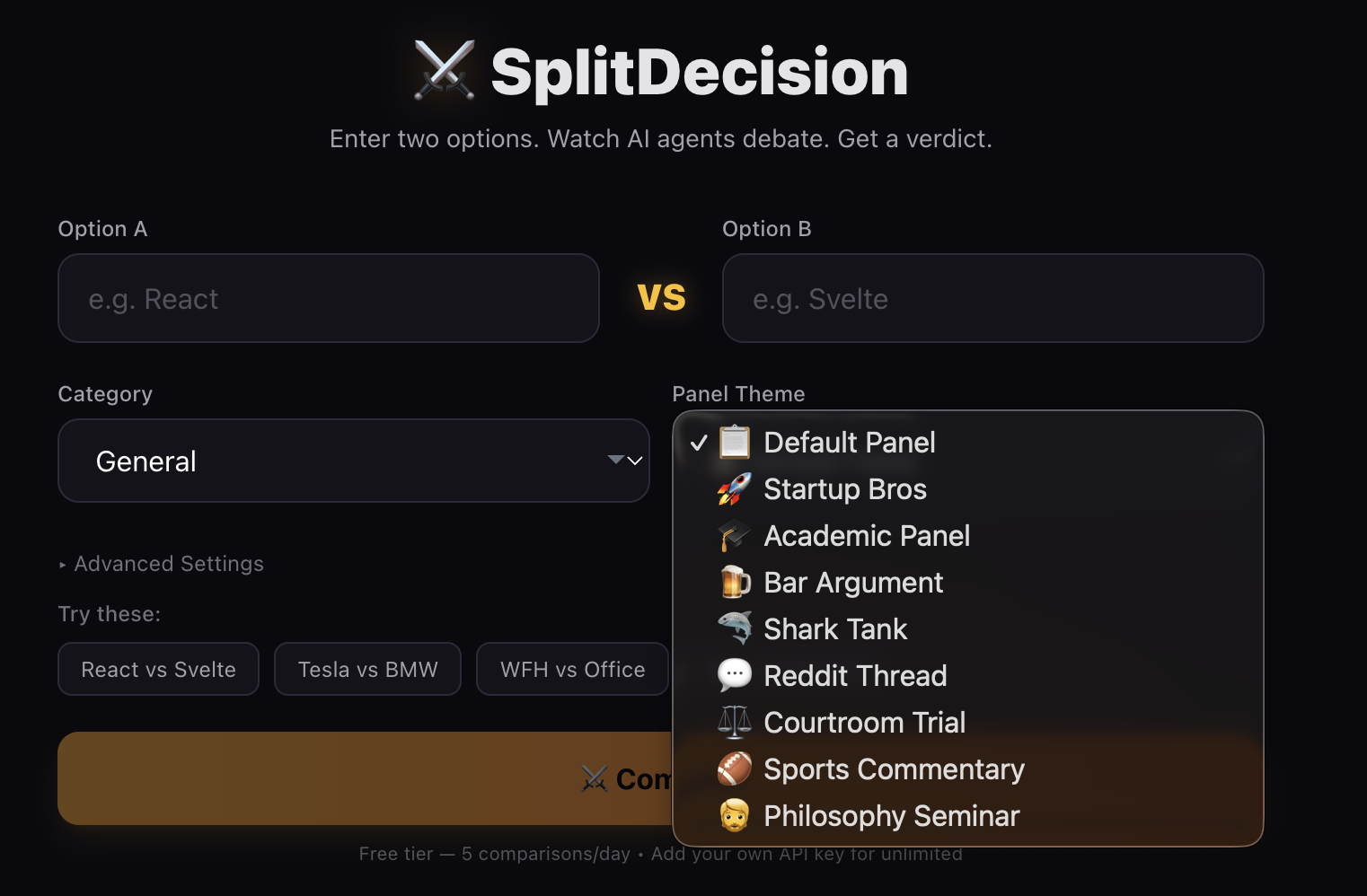
Each theme rewrites all four agent prompts for both rounds, 72 total plus validation and verdict prompts. A “React vs Svelte” debate feels completely different as a Courtroom Trial versus a Bar Argument.
What I Learned
Constraints create character. Without strict writing rules, token limits, and specific vocabulary guidance, all four agents sound the same. The more constraints I added, the more distinct each voice became.
Agent ordering matters. The first agent sets the frame and everyone else reacts to it. The Analyst always goes first, which means it has outsized influence on every debate.
Structured LLM output is fragile. LLMs don’t always follow format instructions perfectly. Clear regex patterns with sensible fallbacks are essential.
Token budgets shape behavior. The Round 2 limit of 250 tokens was the breakthrough. It forced agents to actually engage with each other instead of restating their position.
Streaming changes perception. Watching agents “think” token by token feels like a live event. It’s fundamentally different from waiting for a complete response.
Claude Code made this viable as a solo project. From streaming logic to 72 unique agent prompts, AI-assisted development made the scope manageable.
Wrap Up
Multi-agent systems don’t need to be complicated infrastructure projects. Good prompt engineering, clear agent archetypes, and a streaming-first architecture can create AI interactions that feel like watching a real discussion.
The biggest takeaway? Personality in prompts matters more than model selection. GPT-4o Mini with a great system prompt produces more engaging debates than a larger model with a generic one. The constraints you put on your agents are what give them character.
If you’re interested in building multi-agent systems, start with clearly defined roles, invest time in prompt writing, and let your agents actually interact with each other’s output. That’s where the magic happens.