Why Run AI Locally?
Most people use ChatGPT or Gemini in the cloud, but what if you could run AI right on your own laptop or PC? That’s what I’ve been experimenting with lately, and I like it. And if you’re into self-hosting more broadly, tools like Coolify make it just as easy to spin up your own AI services alongside other apps.
What I like after playing with this:
- Privacy: Prompts never leave your machine.
- Cost: No monthly fees once models are downloaded.
- Learning: You’ll touch concepts like context window and quantization instead of treating AI as a black box.
What Is Ollama?
Ollama is a tool that lets you download and run open‑source LLMs locally with a simple CLI. You pull a model once, then chat with it offline.
Tip: The first run of a model downloads several GBs and can take a few minutes.
Install Ollama
macOS or Linux (Homebrew):
brew install ollama
ollama --version
Alternative (official script):
curl -fsSL https://ollama.com/install.sh | sh
Alternative (official website for macOS, Linux or Windows): https://ollama.com/download/
Run Your First Model
Start small with Gemma 2B:
ollama run gemma:2b
That command will pull the model if it’s not present, then open an interactive prompt.
Good Models to Try
gemma3: Latest Google model, available in multiple sizes (1B,4B,12B,27B).llama3:8b: Strong general-purpose baseline.mistral:7b:Efficient, good reasoning for size.gemma:2b: Fast and light for laptops.phi3:mini: Tiny but capable.
See what you have locally:
ollama list
Specialized Models
Beyond general chat models, there are domain‑specialized models you can run locally:
- Coding: Trained on code and repos. Better at writing/reading code and following tool‑use prompts. Try
codellama:7b-instructas a lightweight starting point. - Medical/Legal/Finance: Domain‑tuned models exist on Hugging Face for specialized terminology and compliance language. Quality varies validate outputs and check licenses before use.
- Vision: Multimodal models like
llavalet you ask questions about images (screenshots, charts, UI states). - Speech:
whispermodels handle local transcription without sending audio to cloud services.
Tips:
- Prefer
*-instructvariants for chat/assistant use. - Start with
q4quantization for laptops increase toq5/q8if you have RAM and want quality. - Always test on your real tasks (sample codebase, sample note set, or representative documents).
Quantization Explained
When browsing models you’ll see two kinds of size info that are easy to mix up:
-
Model size (e.g., 2B, 4B, 7B/8B, 12B, 70B): The number of trainable parameters. Bigger models generally reason better but need more memory and run slower.
-
Quantization (e.g., q4_0, q5_1, q8_0): How many bits are used per weight when loading the model. Lower bits = smaller memory footprint and faster load on CPUs, at the cost of some quality.
Example tag: llama3:8b-instruct-q4_0
-
8b: ~8 billion parameters (model capacity / quality indicator).
-
instruct: Chat-tuned variant for conversational use.
-
q4_0: 4-bit quantization preset (lighter memory use, faster inference).
Memory Usage
Actual usage depends on quantization preset, loader, and whether you run on CPU or GPU but these ranges give you a feel:
-
2–4B q4: ~1–2.5 GB
-
7–8B q4: ~3.5–5 GB
-
7–8B q8: ~7–9 GB
-
13B q4: ~6–8 GB
Run a specific quantized build:
ollama run llama3:8b-instruct-q4_0
If a tag without quantization is used, Ollama selects a sensible default from the library you can always pin an explicit q4/q5/q8 for predictability.
Browse models:
- Ollama Library: https://ollama.com/library
- Hugging Face Hub: https://huggingface.co/models
Use Ollama via API
Ollama also exposes a local API, so you can call models from apps like JabRef or even wire it into your own projects. If you’re curious about the bigger picture, I wrote a post about MCP , which shows how standards like MCP make it easier to connect local LLMs with other AI tools in a consistent way.
Start the server (if not already running):
ollama server
Example curl call:
curl -s http://localhost:11434/api/generate -d '{
"model": "llama3:8b",
"prompt": "Give me three AI project ideas."
}'
You can also use OpenAI-compatible clients by pointing the base URL to http://localhost:11434/.
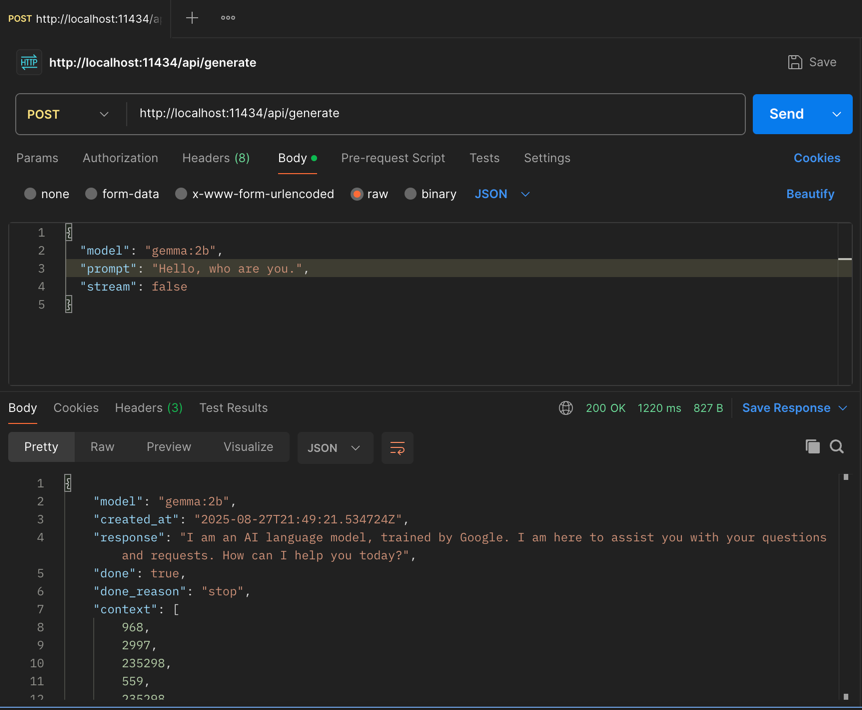
Call Ollama from Postman
Prefer to test APIs visually? You can call Ollama directly from Postman.
- Method:
POST - URL:
http://localhost:11434/api/generate - Headers:
Content-Type: application/json - Body (raw JSON):
{
"model": "llama3:8b",
"prompt": "Summarize why local AI can be useful in 3 bullets.",
"stream": false
}
If stream is false, Postman shows the full response at once. With true, you’ll see a stream of events. Here is how it looks in Postman:
Troubleshooting
- Out of memory? Try a smaller or more quantized model (e.g.,
llama3:8b-instruct-q4_0). - Downloads slow? First pull can be several GB let it finish once.
- Performance feels laggy? Close other heavy apps, or switch to a 2B–7B model.
Use GUI Apps (No Terminal)
If you prefer a GUI app, you can use:
- AnythingLLM: https://anythingllm.com/
- LibreChat: https://www.librechat.ai/
- LM Studio: https://lmstudio.ai/